El Big Data, de la A a la Z



El Big Data es el resultado de numerosos avances tecnológicos que permiten almacenar y procesar grandes cantidades de datos de diversas fuentes de forma rápida y eficaz, pero también es un fenómeno transversal. La explosión de los datos transformando nuestro día a día, la política, la sociedad, las relaciones, la economía, la ciencia e incluso el arte. La exposición Big Bang Data (hasta el 24 de mayo) retrata esta revolución. Intentamos resumir su alcance con estos 27 conceptos.
A de Agrupamiento (Clustering). La tecnología de clústeres permite agrupar varios ordenadores a través de redes de alta velocidad para que funcionen como uno solo. De esta forma, se consiguen máquinas de mayor potencia que permiten procesar grandes cantidades de datos a más velocidad.
B de base de datos. Conjunto de datos almacenados y organizados de forma sistemática para que resulte sencillo encontrarlos, utilizarlos, modificarlos o actualizarlos.
C de Cable. Un gran volumen de datos viaja por todo el mundo a través de cables. Algunos de ellos se extienden a lo largo de miles de kilómetros bajo los océanos y los mares y conectan islas y países. En la exposición Big Bang Data puede verse un enorme mapa de los cables submarinos del mundo que no solo da una idea sobre las conexiones del planeta, sino que también ayuda a entender la geopolítica mundial.

D de Datificación. Este término se utiliza para definir el fenómeno de explosión de los datos en el que estamos inmersos y que se explica en la exposiciónBig Bang Data. La capacidad de almacenar y procesar un volumen inmenso de datos está transformando la sociedad y nos está transformando como individuos. Los datos son fuente de riqueza y de conocimiento, pero también una herramienta de vigilancia de la que puede aprovecharse el poder. La datificación del mundo es una realidad y es consecuencia directa del Big Data.
E de Estadística. Disciplina que estudia y analiza datos y extrae conclusiones de ellos. La gran riqueza del Big Data es el beneficio que podemos extraer del análisis e interpretación de esos datos.
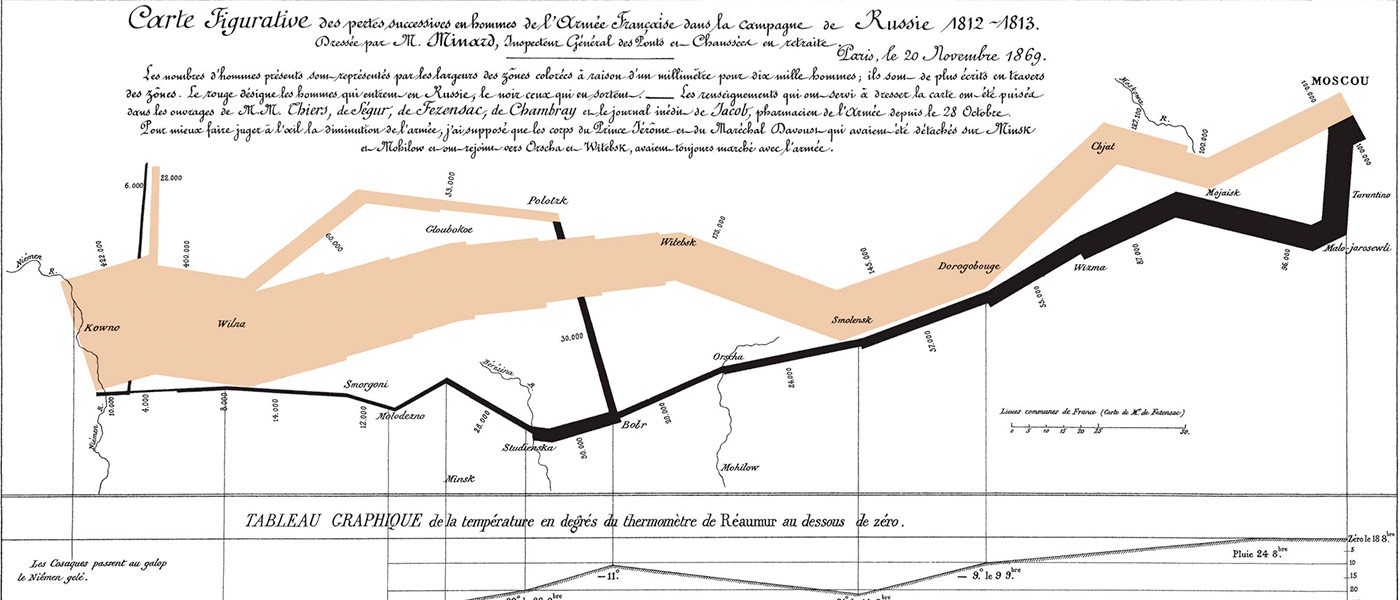
F de Flujo (mapa). Los mapas de flujo son un tipo de infografía, una fórmula para visualizar e interpretar datos. En los mapas de flujo puede observarse el movimiento y las variaciones que ha sufrido un objeto al desplazarse de un punto a otro (comercio, flujos migratorios…). Una de las infografías más reconocidas de la Historia es un mapa de flujo que muestra las bajas que sufrieron las tropas de Napoleón en su campaña para invadir Rusia. Un mariscal de campo llevó el recuento de las muertes de los soldados de forma manual y, décadas después, el ingeniero Charles Joseph Minard transformó aquella rudimentaria ‘base de datos’ en un mapa de flujo. En Big Bang Data puede verse un facsímil de aquel célebre gráfico.
G de Geolocalización. Solo con llevar el teléfono móvil en nuestro bolsillo, estamos cargando con decenas de sensores que registran nuestra actividad y emiten datos. La geolocalización genera datos constantes y abundantes que pueden ayudarnos a comprender mejor el mundo que nos rodea. En el reportaje Madrid en datos puedes ver algunos ejemplos de lo que se puede visibilizar con datos procedentes de la geolocalización a través de los smartphones.
H de Huella digital. Se llama huella digital al ‘rastro’ que dejamos los usuarios al usar internet y las redes sociales y que, de alguna forma, define nuestra identidad en la Red. Las fotos y vídeos que compartimos, las imágenes en las que nos etiquetan, los mensajes que publicamos, las búsquedas que realizamos, los ‘me gusta’ que damos… Todos estos datos forman parte de nuestra huella digital y cuanto menos protejamos nuestra privacidad más fáciles serán de encontrar. ¿Qué huella dejan los turistas a su paso por Madrid? ¿Qué huella dejan tus compras? ¿Qué rastro dejan tus llamadas? Puedes verlo en este especial:
I de Internet de las cosas. Teléfonos, ordenadores, libros, cámaras, relojes, pulseras, gafas, ropa, coches… Cada vez más objetos de nuestra vida cotidiana son inteligentes y están conectados a la Red. Estos dispositivos nos transforman en una sociedad siempre conectada que produce datos constantemente.
J de John Mashey. Los orígenes del término ‘Big Data’ no están claros. Las palabras ‘big data’ son muy comunes y resulta complicado encontrar quién las utilizó primero con el significado que tienen hoy. El economista Francis X. Diebold se atribuyó la creación del término en 2003, el año en que publicó su investigación académica Big Data Dynamic Factor Models for Macroeconomic Measurement and Forecasting. Sin embargo, Diebold siguió investigando sobre el origen de este concepto y concluyó que no era suyo. Todo apunta a que John Mashey, un ingeniero de la empresa tecnológica Silicon Graphics, fue quien utilizó por primera vez la expresión Big Data en 1990. Aquí puedes leer una entrevista de The New York Times a Mashey, Diebold y otros expertos relacionados con la etimología del Big Data.

K de KeyValue. Estructura de bases de datos que organiza la información a través de palabras clave. Se trata de una estructura muy simple, sencilla y escalable con buen rendimiento. Esta estructura nació para compensar las carencias de las bases de datos para hacer frente a grandes cantidades de consultas.
L de Lectores biométricos. Existen muchas tecnologías capaces de extraer datos del cuerpo humano: reconocimiento facial, lectores de iris, de retina y de huella dactilar, pruebas de ADN… La medicina y la investigación ya se están aprovechando de las posibilidades del Big Data, pero el gran público tiene cada vez más acceso a los lectores biométricos gracias a la tecnología wearable.
M de Minería de datos. Disciplina que se dedica a detectar tendencias, relaciones y patrones en grandes volúmenes de datos usando herramientas como la inteligencia artificial o la estadística.
N de Nube. La Nube es la metáfora con la que nos referimos a los servicios que se ofrecen a través de la Red. La Nube nos permite utilizar aplicaciones y archivos sin tener que descargarlos o almacenar ficheros para poder acceder a ellos desde cualquier dispositivo. Sin embargo, es una metáfora tramposa. El nombre nos evoca volatilidad y ligereza, pero en realidad la Nube ocupa mucho espacio, es grande y pesada. Las aplicaciones y los archivos se alojan en enormes Centros de Datos, naves inmensas con cientos de ordenadores que funcionan sin descanso. Aquí puedes descubrir más cosas sobre los Data Centers, las catedrales de internet. Uno de los centros de datos mejor preparados del mundo se encuentra situado en Alcalá de Henares, en la Comunidad de Madrid, y pertenece a Telefónica. Es uno de los tres centros de datos que cuentan con la categoría Tier-IV Gold.
Ñ de España. En nuestro país, compañías como Telefónica I+D, el Centro de Innovación BBVA, Amadeus, Beeva o Capside trabajan en el sector del Big Data. Proyectos como Big Bang Data o las conferencias Vivir en un Mar de Datos de Fundación Telefónica se dedican también a la divulgación de este asunto. En el blog Big Data 4 Success recogen algunos de los nombres más importantes del Big Data en nuestro país.
O de Open Data. Movimiento que reivindica que ciertos datos sean públicos y estén disponibles para la ciudadanía. En España podemos encontrar casos como el de Civio, una fundación que aplica esta idea para reclamar una mayor transparencia, rendición de cuentas del poder político y una democracia más participativa. Civio ha puesto en marcha proyectos como Tu derecho a saber, El Indultómetro, España en llamas o El BOE nuestro de cada día.
P de Privacidad. El Big Data abre también un debate ético interesante, ya que convierte los datos de los usuarios en un valor, en un producto y en un negocio para muchas corporaciones. Los perfiles de las redes sociales, donde los usuarios comparten sus gustos y sus intereses, contienen una información muy jugosa para las marcas, que ven su oportunidad para segmentar mejor y afinar muchísimo más a la hora de colocar sus productos. La legislación europea de protección de datos dice que todo individuo tiene derecho a recibir una copia de toda la información personal que una compañía ha recogido sobre él. Max Schrems, un estudiante de derecho de Austria solicitó a Facebook que le enviara toda la información que hubiera recogido de su cuenta. Facebook le remitió un documento de 1.200 páginas que ahora se encuentra expuesto en Big Bang Data. La la huella digital que dejamos en la Red y la venta de datos producen grandes dilemas éticos y legales que todavía están por resolverse.
Q de Query. Un ‘query’ es una pregunta que se realiza a una base de datos utilizando un lenguaje de consulta (o lenguaje ‘query’) con el objetivo de recabar información.
R de Rack. Los rack son los bastidores en los que se colocan los ordenadores de los centros de datos. En cada uno de estos ‘armarios’ se sitúan los ordenadores que alojan y procesan los datos de usuarios y empresas.
S de Servidor. Un servidor es un ordenador que ofrece un servicio remoto a otro ordenador. Este servicio puede ser desde el uso desde una aplicación hasta la descarga o el almacenamiento de datos.
T de Transactional Data. Datos dinámicos que cambian a lo largo del tiempo.
U de Usuario. Cada segundo se publican 6.000 tweets. Cada minuto se suben 300 horas de vídeo a YouTube. En un solo día, se suben 300 millones de fotos a Facebook. Los usuarios nos hemos convertido en los grandes creadores de contenido en la Red. Generamos datos constantemente y contribuimos, incluso sin saberlo, al fenómeno del Big Data.
V de Visualización de datos. El influyente infografista Jaime Serra define la infografía como “una herramienta de comunicación de alta precisión que utiliza, de forma combinada e indivisible, dos lenguajes: palabra e imagen”. La visualización de datos es la representación de los datos a través de infografías para comunicar la información que contienen. Para saber más sobre la infografía y la visualización de datos, puedes leer esta entrevista con Jaime Serra, cuyos trabajos también se exponen en Big Bang Data.
W de World Wide Web. El Big Data es un fenómeno horizontal que afecta a muchísimos asuntos, pero la revolución de los datos que estamos viviendo en la actualidad está íntimamente ligada a internet, la Web y las redes sociales.
X de XML. Lenguaje diseñado para describir, analizar y procesar datos de forma fácil entre diferentes aplicaciones independientemente del origen de los datos. Las bases de datos documentales suelen encontrarse en formato XML.
Y de Yottabyte. En la actualidad, el total de los datos que existen en el mundo es de un Yottabyte. Para almacenar esa cantidad de información, tendrías que comprarte más de un billón de discos duros de un ‘tera’ (1000 ‘gigas’).
Z de Zettabyte. Los ‘gigas’ se nos han quedado pequeños (un portátil con una capacidad de almacenamiento normal ya supera fácilmente los 500 ‘gigas’) y medimos en ‘teras’ con más frecuencia (un ‘tera’ son unos 1.000 ‘gigas’; hace años que se comercializan discos duros con capacidad superior a un ‘tera’). Dentro de poco nos olvidaremos de los ‘teras’ y empezaremos a pensar en petabytes (1 petabyte es algo más de 1.000 ‘teras’). Para medir la cantidad de datos que se generan anualmente tenemos que irnos hasta los zetabytes. Cada año se producen en el mundo 2,8 zetabytes de información, unos 3.000 millones de ‘teras’. ¿Cuánto nos queda para pensar en Zettabytes?
Con información de Wikipedia, Datafloq, Big Bang Data, Information Graphics: A Comprehensive Illustrated Reference (Robert L. Harris).
Por Víctor Navarro.